信也科技是在纽交所上市的金融科技集团,致力于通过大数据、人工智能、区块链等技术实现“科技,让金融更美好”的使命,推动金融服务从可获得进一步向可负担、可信任和可享受进化,成为受用户欢迎、受伙伴信任的金融科技品牌。信也科技旗下包括金融科技业务、国际业务、科技生态孵化业务三大板块,具体涵盖消费金融、科技输出、孵化器和投资等业务,坚持以创新技术服务大众、赋能机构,助力实体经济发展。
一、业务背景
公司销售业务快速发展,用户对多维数据分析的实时性要求越来越高,场景也变化多样,业务的复杂性和多样性给公司研发和运维成本带来很大的挑战。与此同时开源数据分析引擎也是百花齐放,日新月异。信也科技实时数据团队致力于研发效率最大化,选择一款合适高效的存储引擎就尤为重要。信也科技通过引入新一代性能彪悍的MPP架构数据库StarRocks来构建实时数仓平台,进行实时数据分析,提供统一的数据服务;降低业务使用复杂度,提升用户体验,实现生产效率最大化。
二、原有架构及痛点
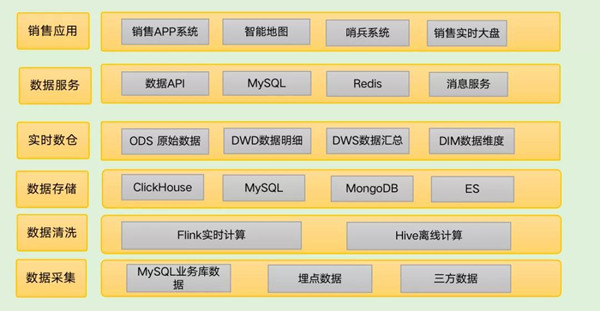
销售数据平台初期分四个子项目:
销售APP系统:实时消费业务库Binlog数据,通过Flink实时消费清洗,计算不同维度下的销售订单和业绩等指标,按时、按天、按月等时间维度进行实时计算,数据落到MySQL/MongoDB。
销售智能地图系统:为了更好的分析销售行为和跟踪销售轨迹,关注销售的订单,业绩等指标,数据经过流转和清洗完之后,除了发一份数据到MySQL之外,最后还要推送一份数据到Elasticsearch中,引入Elasticsearch的原因一是用到地图GEO函数,二是灵活地支持多种维度查询。
销售实时大盘:清洗完的数据(订单、业绩等)发送到消息中间件,然后落到Redis、MySQL等存储系统中供前端使用。
销售消息推送系统:数据(订单、业绩)经过清洗之后,会发一份数据到ClickHouse中,最后实时推送数据,以满足不同的场景。
为了快速响应业务需求,满足不同的业务场景,团队选择不同技术方案来快速满足业务需求,项目的初期很好的满足了业务需求,随着时间的推移,数据量和业务功能变的越来越复杂,同时业务口径变更和新需求的不断提出,项目的维护成本和痛点就越来越明显:
同一份数据存储多份,浪费存储资源。
新需求或需求变更所涉及的团队和数据存储,数据服务比较多,沟通成本和研发成本相应增加。
多层级组织架构下进行计算和统计分析业绩、订单、标的等指标,这些指标在不断变化的维度和不同的计算口径下给系统带来很大的挑战,很难快速响应业务需求。
多种存储引擎和多套数据服务带来巨大的运维成本和整体系统的不稳定性因素和隐患也相应增加。
三、OLAP引擎选择
根据目前的业务痛点和业务本身对数据多维分析查询的要求,以及能适应公司未来在线实时查询需要,我们选择一款OLAP引擎要有几点要求:
·低延迟的毫秒级响应,数据秒级写入。
·运维简单,易用性强。
·复杂的场景查询。
·明细数据查询。
·多表关联查询性能好。
·支持高并发。
·对地图函数有支持。
·要有物化视图的能力。
StarRocks
优势:
·支持标准SQL,兼容MySQL协议以及分布式Join。
·水平扩展,不依赖外部组件,方便缩扩容。
·支持多种聚合算子,物化视图。
·MPP架构,分片分桶的复合存储模型。
·支持高并发查询,QPS可达千、万量级。
·支持宽表和多表Join查询,数据查询秒级/毫秒级。
·支持地图GEO函数。
·运维简单,易用性强。
·复杂的场景查询。
劣势:
·缺乏单列数据更新能力。
·周边生态还不是很完善。
ClickHouse
优势:
·数据压缩,多核并行处理,单表性能极佳。
·向量引擎,稀疏索引,适合在线查询。
·支持数据复制和数据完整性。
·支持地图GEO函数。
劣势:
·没有完整的事务支持以及多表Join不友好。
·对修改或删除数据的能力支持不够,MergeTree合并不完全。
·并发能力不高。
·依赖Zookeeper,在集群扩大时ZK会成为性能瓶颈。
TiDB/TiFlash
优势:
·数据压缩,多核并行处理,单表性能极佳。
·支持标准SQL,兼容MySQL协议以及分布式Join。
·TiFlash预处理加速OLAP分析。
·TiDB计算、存储分离,高可用模式,运维依赖于自动化运维工具,易操作。
·支持高并发查询。
劣势:
·强依赖SSD,硬件成本比较高。
·OLAP场景下查询性能相对弱一些。
·不支持实时预聚合。
·不支持地图GEO函数。
早期应用的OLAP引擎各自有一些功能局限,无法满足我们的需求。如Presto、Impala无法提供低延迟亚秒级响应,Druid不提供明细查询,Kylin无法基于明细提供毫秒级查询,更多场景是预计算,运维成本也比较高。这次通过对比StarRocks、TiDB/TiFlash、ClickHouse这些当下性能卓越的开源引擎,我们基本上锁定了StarRocks作为我们新一代的MPP架构的OLAP引擎。
四、销售平台现有架构
引入StarRocks后,架构如下图所示:
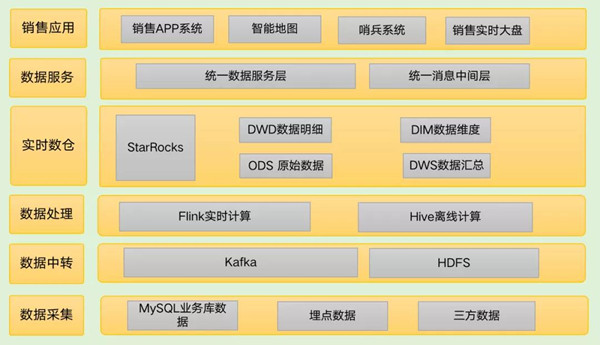
数据采集
线上关系型业务库数据通过Canal实时采集MySQL Binlog到Kafka,离线数据通过Sqoop/DataX工具导入到HDFS中,埋点数据通过自定义Kafka的Log Appender,数据会实时写入Kafka,供下游消费。
数据中转
Kafka作为业务库实时数据的中转站,保留一定时间的数据,作为实时数仓的ODS,为下游计算准备数据,HDFS作为业务库历史数据中转站,是一次性的数据,保留一段时间后可以删除,节省成本。
数据处理
实时数据:根据需求,我们通过Flink实时消费Kafka数据进行数据清洗、关联、处理等操作,然后通过Flink-StarRocks Connector把数据落到StarRocks中。
离线数据:通过HDFS调度平台对离线数据进行清洗、处理,然后通过StarRocks导入工具把数据一次性落入到StarRocks中。另外,我们的业务数据也会更新变化,比如订单状态等,我们选择更新模型来满足需求。
实时数仓
实时数仓层的数据根据数据仓库典型逻辑分层划分为ODS、DWD、DWS、DIM等层,不同分层的数据,可以通过Flink实时计算直接落库,也可以通过离线调度平台进行分钟级或小时级的调度计算,当然也可以利用StarRocks本身的物化视图,这个要根据不同场景进行选择。总体来说我们会利用StarRocks极速的OLAP查询能力(分区分桶,向量化计算,列式存储,MPP架构)和不同的数据模型(明细模型、聚合模型和更新模型)来满足不同场景的数据分析需求。
数据服务
目前这套架构通过两种方式对外提供服务,一是提供数据服务接口供各个应用方使用,二是把数据发送到消息中间层(公司自研消息中间件)供下游使用。目前数据主要面向管理层、运营人员、B端用户,数据查询要求低延迟,需求变化快,而StarRocks通过极速的性能、高并发低延迟的特性以及灵活的建模方式很好满足了这些用户的数据需求。
销售应用
基于目前销售数据我们在上层构建了各种应用,比如APP后端系统、实时大盘、哨兵系统、智能地图、运营推荐系统等,来满足业务方的需求。
可以看到,引入StarRocks之后,新架构具有如下的优点:
·统一数据存储计算引擎,有助于打破数据壁垒,实现数据价值最大化。
·统一数据管理,降低管理复杂度,提升数据安全性。
·统一数据服务计算,复用已有接口,研发效率最大化。
·灵活多变的维度组合查询,快速响应业务需求。
五、StarRocks运维
基于Prometheus+Grafana进行监控
除了StarRocks本身提供的Manager管理功能,StarRocks也提供了基于Prometheus+Grafana的可视化监控方案。Prometheus通过Pull方式访问FE/BE的Metric接口,将监控数据存入时序数据库,然后通过Grafana配置Prometheus为数据源,自定义绘制Dashboard。通过这套方案,我们初步搭建了StarRocks运维监控体系来保障线上服务。
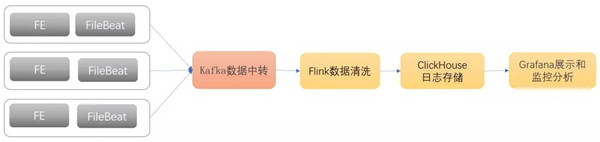
基于日志的审计监控
SQL慢查询,响应时间长,不规范的SQL会给整个平台带来不稳定的因素,另外还有些大批数据导入可能会带来短时间的CPU、IO等压力,这些操作我们都需要监控到,避免带来不必要的麻烦,目前我们是通过FileBeat去采集FE上审计日志信息,然后插入ClickHouse,然后在Grafana上展示出来,对这些SQL进行分析和监控,以便可以更好的进行优化。
六、未来规划
StarRocks作为新一代极速全场景MPP数据库,引入了StarRocks之后,实现了统一存储,统一服务,并且在多种场景下表现出色,帮我们实现了产出价值最大化。未来我们对StarRocks也进行了一定的规划:
根据业务场景不同,对响应时间要求不同,搭建多套StarRocks集群,进行物理资源隔离。
将更多的在线实时任意多维度分析业务迁移到StarRocks,打造统一的实时数仓平台。
数仓体系升级加速,提升用户极速体验,探索使用StarRocks打造实时数仓和离线数仓融合和一体化建设。
打通数据接入平台和数据开发平台,完善运维监控体系,保证大数据基础服务的稳定性。(作者:余荣幸,信也科技大数据资深专家)
来源:中国资讯报道网
 京公网安备 11010502045281号
京公网安备 11010502045281号主办:华夏经纬信息科技有限公司 版权所有 华夏经纬网
Copyright 2001-2024 By www.huaxia.com

![]()



{kind=link}
{kind=link}